

はじめに
このブログ記事は、最新AIを活用した英会話学習の体験から、理想の学習環境を求めて自作アプリを開発するまでの記録をまとめています。
記事の構成は、大きく以下の2つのパートに分かれています。
✅ 前半:Gemini Liveでの英会話練習と、そこで感じた「もどかしさ」
既存のAIサービス(Gemini Live)を英会話パートナーとして使ってみて分かった、AI特有の「忖度」や「間の取り方」の難しさ、そして構造的な限界について分析しています。
✅ 後半:エージェント型開発プラットフォーム「Antigravity」によるアプリ開発
「プログラミングコードを1行も書かずに」理想の英会話アプリをどう形にしたのか。GoogleのAntigravityをパートナーとした、具体的な開発工程を紹介しています。
特にアプリ開発の流れや、AIエージェントの活用方法に注力して読みたい方は、以下のセクションから読み進めていただくのがおすすめです。
もしお時間があれば、ぜひこのまま読み進めてみてください。
Geminiとの英会話で感じるもどかしさ
GoogleのAI「Gemini(ジェミニ)」は日々進化を遂げ、私たちの生活をより豊かにしてくれています。特にリアルタイムで音声会話ができる「Gemini Live」は、英会話の学習パートナーとして非常に画期的なツールです。
しかし、いざ実際に英会話の練習に使ってみると、どこか「カユイところに手が届かない」というもどかしさを感じる場面も出てきました。
私が気になったのは、主に次の2点です。
✅ 文法がメチャクチャでも、カタカナ英語でも、聞き取ってしまう:
文法や発音の正確さよりも、まずは英語が反射的に口から出る状態を目指す。そんな方にとって、AIの高い理解能力はまさにうってつけです。
私のつたない経験でも、一番の障壁はミスそのものではなく、正解を気にして黙り込むことでした。まずは、メチャクチャな英語でも意図を汲み取ってくれるAIを相手に、躊躇なく言葉を発する練習は意義高いものだと思います。
ただ、もう一段上のレベルを目指そうとするときには、あえて忖度せずに厳しく判定してくれる機能が欲しいところです。この両者をうまく切り替えられると嬉しいですね。
✅ 間の取り方がいまいち:
Gemini Liveでの会話中にはこんなことがありました。
・こちらが答えを考えていると、すかさず言葉を被せてくる。
・一方で「少し間をとって」と言うと、発話するまで待ち続け沈黙が流れる。
期待しているのは「考える時間の確保」と「その後の助け舟」の両立ですが、この阿吽(あうん)の間を実現することができません。
Geminiを英会話のパートナーにするためのハードル
Gemini Liveに向かって英語で話しかければ、自然な英語で返答してくれます。
ただ、普通に話されると、ついていけないので、
・ ゆっくり話をして
・ 簡単な単語を使って
・ 言葉に詰まったら少し待って
などと、お願いします。
ただ、このようにお願いをしても、思い通りに応対してくれることもあれば、そうでないこと(例えば、そもそも対応してくれない、対応が少々ズレている、対応してくれる時とそうでない時がある、などということ)もあり、もどかしさを感じます。
ただ、対応してくれない原因は、AI特有の構造的な理由が関係しているのかもしれません。
生成AIも物忘れをする
AIも人間同様、会話が進むにつれて初期の指示を忘れてしまう傾向があります。
通常のチャット形式では、最初に出した指示も「会話履歴(ログ)」の一部として処理されます。やり取りが長くなりログが積み重なると、最初に与えた重要な役割やルールが膨大なデータの中に埋もれてしまいます。
その結果、いつの間にかAIがお願いを忘れ、ただの「聞き上手な話し相手」に戻ってしまうという限界があります。
会話中のお願いよりも、更に強い制約がある
英会話の練習中、言葉が出てこず沈黙してしまうのは誰にでもあることです。そんな時、AIに「沈黙したときは間を少し間を空けて」とお願いすると、今度は「ユーザーから次の入力があるまで待ち続ける」という極端な挙動をとってしまうことがありました。これは、お願いの仕方が適切でないのか?、そうではないかもしれません。
生成AIには、会話ウィンドウ経由でのお願い(「ユーザープロンプト」)よりもはるかに強制力のある「システムプロンプト」という内部命令が存在します。あらかじめこの内部命令でルールが固定されている場合、いくら会話の中で設定変更をお願いしても、AIがその枠組みを自ら書き換えることはできないのが一般的です。
さらに、AIを使ったサービスが持つ仕様制約も存在します。こうした制約を超えるようなリクエストを、会話を通じて指示しても、もちろんそれを実現することはできません。
「もっとこうしてほしい」という理想があるのに、手が届かない。そんなもどかしさを解消する1つの答えは、「無いのであれば、自分の理想を詰め込んだアプリを作る」という発想です。
かつて、この道は高度なプログラミングスキルを持つ一部のエンジニアにしか開かれていませんでした。しかし今、生成AIの劇的な発展により、その高い壁が取り払われようとしています。
今こそ注目したいのが、生成AIを活用した自作アプリケーション開発です。AIのポテンシャルを引き出す仕組みを整えれば、理想とするものを自分とAIの共創で作れる時代が近づいてきています。
英会話アプリGenAI Talkの試作
そんなわけで欲しい機能を盛り込んだ英会話アプリを試作してみました。今回開発にはGoogleのAntigravityを使用しました。
「せっかくなら無料で皆さんに使ってもらいたい」と思い、配布も考えて開発を進めていたのですが、多種多様な端末(画面サイズ)やOSバージョン、様々な通信環境において、一定レベルの動作を保証するための検証に十分な時間を割くことが難しく、配布を断念することとしました。
汎用性については未知数ですが、個人で利用する範囲内では、十分に満足のいく仕上がりになっています。
この開発をするにあたって、私はプログラム(ソースコード)を1行も書いていません。それでも作りたいアプリのイメージがあれば、こんなレベルのことなら実現できるんだ、ということがイメージしてもらえると嬉しいです。
では、アプリの紹介、そのアプリ開発の裏側、という順で話をすすめていきます。
生成AI英会話アプリ「GenAI Talk」の紹介
- いつでも・どこでも:
AIが相手なので、時間や場所を選ばず、自分のペースで話せます。 - マイクに向かって話すだけ:
文字入力は不要です。マイクに向かって話すだけで、AIがあなたの言葉をリアルタイムで理解し、音声で返事をしてくれます。 - レベル・役割設定:
レベル(初級・中級・上級)、役割(英会話の先生・親しい友人)、声のトーンなど、気分に応じて、英会話パートナーの役割を変えることができます。
使い方(簡易版)
- 設定: 画面の「Settings」から、自分のレベルや好きな声を選びます。
- キー入力: 取得したAPIキーを貼り付け、「同意事項」にチェックを入れます。
- 開始: 「保存して開始」を押すと、会話画面に切り替わります。
- 会話:まず「START]ボタンを押すと会話開始です。AIが「Listening」状態になったら英語で何か話しかけてください。終わる時は「STOP」を押します。
アプリで設定できる項目
今回の試作アプリでは、こんな感じの設定項目を用意しています。
Persona Level(英語のレベル設定)
- Beginner(初級): 短く簡単な文章で、ゆっくり話してくれます。
- Intermediate(中級): 標準的な長さの文章で、自然なスピードで話します。
- Advanced(上級): ネイティブ同様の語彙とニュースのようなスピードで話します。
Voice(AIの声質の選択)
- Puck: フレンドリーで聞き取りやすい男性の声です。
- Charon: 深みのある落ち着いた男性の声です。
- Kore: 温かみのある親しみやすい女性の声です。
- Fenrir: 元気でエネルギッシュな男性の声です。
- Aoede: 穏やかで知的な女性の声です。
Role(AIの役割の選択)
- Teacher(先生): 発音や文法を丁寧に指導してくれるモードです。
- Friend(友達): カジュアルな日常会話を楽しめるモードです。
Creativity(AIの発話内容の独創性)
- バーを左(Strict)に寄せると、教科書通りの正確な英語を重視します。
- バーを右(Creative)に寄せると、AIが自由に発想した豊かな表現を使います。
Silence Follow-up(沈黙時の間の取り方)
- あなたが沈黙してしまった際、AIがどれだけの時間待って声をかけるか(フォローアップ)を制御する機能です。1.0秒から10秒まで0.1秒単位で設定可能で、10秒を超える設定すると「Disable(無効)」になり、AIからの自発的な声掛けは行われず、あなたからの発話を待ち続けます。
Session Time(会話時間)
- STARTボタンを押し会話を開始してからそのセッションが終了するまでの時間です。1分から15分の間で設定できます。
- GoogleのAPIの無料プレビュー枠を使用しており、その制限により最大15分となっています。
Show Captions(字幕表示)
- AIや自分の話した内容を画面に文字として表示するかどうかを切り替えます。
この機能要件を元に、英会話アプリのプロトタイプを作ってみました。出来上がったアプリの画面はこんな感じです。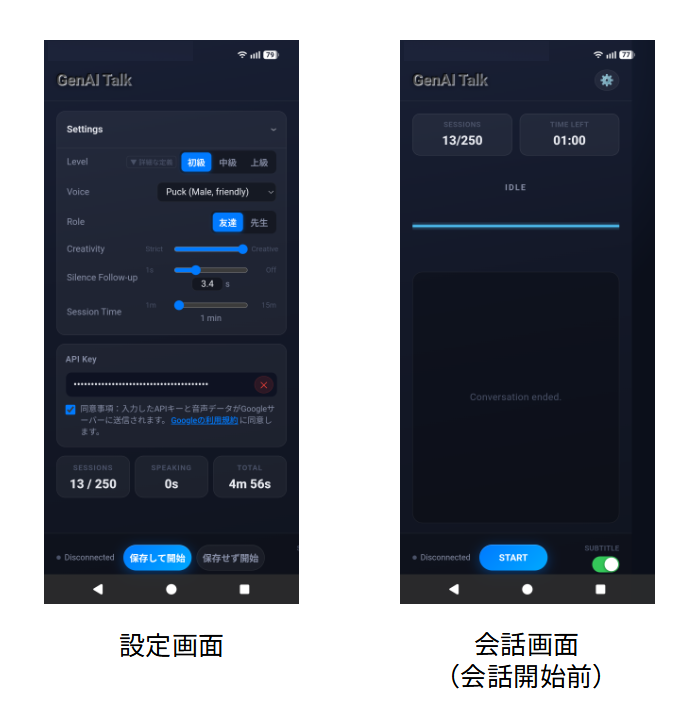
さて、ここからは「この英会話アプリをどうやって形にしたのか?」という裏側の話に移ります。「自分専用のツール」を作り上げる、生成AI(GoogleのAntigravity)をパートナーとしたアプリの開発フローに興味がある方はぜひ読み進めてみてください。
AIとの共創による英会話アプリの開発フロー
今回、Gemini Liveを使用した英会話練習では少々使いにくさを感じるところがあり、Geminiを活用した自作英会話アプリを作ることにしました。
この自作のアプリ開発において、コーディングスキルを持たない私がパートナーに選んだのはエージェント型開発プラットフォームであるGoogleの「Antigravity」です 。
アプリ開発といっても、私自身はプログラミングコードはほぼ書けません。エージェント型開発プラットフォーム「Antigravity」というツールを使い、私は「どんなアプリにしたいか」という設計図を考え、具体的な実装(コード作成)はAIに任せるというスタイルをとりました。
開発にあたっての目標
今回の開発を進めるにあたり、まず以下の2つのゴールを設定しました。
- 1. 指示の徹底: システムプロンプトを利用し、チャット(ユーザープロンプト)よりも深い階層で、英会話のパートナーとなるAIの役割を指定する。
- 2. スムーズな会話の実現: Gemini Liveと同等のストレスのない会話体験を構築する。
これらの目標のうち、特に2つ目の「スムーズな会話」については、専門知識が無いため具体的な実装案を持っていませんでした。そこでAIにどんな実現案が存在し、それらのメリット・デメリットを整理してもらい、おすすめのソリューションを提案してもらいました。提示されたソリューションが妥当であり、特に懸念すべき点も見当たらなかったため、AIの提案を採用することに決定しました
- Gemini 2.5 Flash Native Audioの採用: 音声を直接処理できる最新の特化型技術を利用。これにより、従来のテキスト変換を介さない、タイムラグを極限まで抑えた自然な対話環境を目指します。
- セキュリティに配慮したBYOK方式: Gemini 2.5 Flash Native Audioを使用するにあたりAPIキーが必要となります。APIキーの管理については、ユーザー自身が自分のキーを持ち込んで使用する「Bring Your Own Key(BYOK)」方式をAIが提案。開発側がキーを預からない仕組みにすることで、利用者の安心感と透明性を確保しました。
仕様設計:開発要件の策定
先ほど決めた目標を土台として、開発要件を定めました。ここでも専門知識が必要で私が把握できていないものについてはAIと相談しながら策定しました。今回策定した開発要件定義の内容を参考までに共有します。
【英会話アプリ GenAI Talk 要件定義書】
第1章:アプリケーション概要
REQ-1.1 基本コンセプト
本アプリケーションは、GeminiのAPIを活用し、低遅延で自然な双方向の英会話体験を提供する。
REQ-1.2 使用対象機器
本アプリケーションのターゲットはスマートフォンおよびPCとする。
REQ-1.2.1 PC利用時: Webブラウザ上で稼働する。
REQ-1.2.2 スマートフォン利用時: PWAとしてブラウザから利用できるほか、Capacitorを用いたネイティブアプリ(Android)としても動作する。
REQ-1.3 APIキー管理(BYOK)
REQ-1.3.1 BYOK(Bring Your Own Key)モード: ユーザー自身が取得したGemini APIキーをアプリケーションに入力し、ユーザー自身の利用枠の範囲内で利用可能とする。
REQ-1.3.2 APIキーの保存(localStorage): 入力されたAPIキーは localStorage に永続化し、ユーザーの操作によっていつでも削除可能とする。
第2章:システム構成・アーキテクチャ
REQ-2.1 フロントエンド技術
REQ-2.1.1 フレームワーク: Vite + React による SPA 構成とする。完全なクライアントサイド・レンダリング(CSR)を行い、静的ファイルとしてビルド可能な構成とする。
REQ-2.1.2 ハイブリッド対応: Capacitorを採用し、ウェブのソースコードからAndroidネイティブパッケージ(APK)の生成を可能とする。
REQ-2.1.3 PWA対応: manifest.json を備え、スマートフォンのホーム画面に追加してフルスクリーンUI(standalone)で利用可能とする。
REQ-2.2 通信プロトコル
REQ-2.2.1 API接続: ブラウザから直接 Google Gemini に対して WebSocket 接続(Multimodal Live API)を確立する。
REQ-2.2.2 通信リカバリー(自動再接続): ネットワーク瞬断等の切断検知時に自動再接続(最大5回)を試みる。再接続時はセッションがリセットされるため、システムプロンプトに「接続断による文脈喪失のお詫びと説明」を自動挿入し、AIがスムーズに会話を再開できるようにする。
第3章:機能要件
REQ-3.1 英会話コア機能
REQ-3.1.1 リアルタイム音声対話: Gemini Multimodal Live API を用い、音声入出力による即時応答の双方向対話を実現する。
REQ-3.1.2 キャラクター・レベル設定:
REQ-3.1.2.1 レベル選択: Beginner / Intermediate / Advanced の3段階。
REQ-3.1.2.2 レベルの定義は1つのファイル内に集約。このファイルに記載された定義を会話開始前にシステムプロンプトでAIに通知する。レベルの初期値設定は以下の通り。
[Level: Beginner]
– Speech Length/Complexity: Keep your responses very brief, strictly 1 to 2 short sentences (around 10 words total). Do NOT use complex vocabulary or idioms.
– Speed: Speak SLOWLY, as if you are speaking to a upper grade elementary school students.
– Language Support: If the user doesn’t know how to say something and speaks in Japanese, you MUST respond by teaching them how to express that exact thought in English first, and then continue the conversation.
[Level: Intermediate]
– Speech Length/Complexity: Keep your responses to 2 to 3 sentences (about 20-30 words). Use conjunctions and maintain a natural but accessible information density.
– Speed: Speak slightly slower than normal speed.
– Language Support: You do NOT understand any language other than English.
[Level: Advanced]
– Speech Length/Complexity: Speak at a standard, natural length with rich vocabulary and native-level expressions.
– Speed: Speak at a normal native speed, or slightly fast.
– Language Support: You do NOT understand any language other than English.
REQ-3.1.2.3 詳細編集機能: 各レベルの定義(システムプロンプト)をユーザーが画面上で直接編集・保存できる機能を提供する。
REQ-3.1.2.4 役割(Role): teacher(先生)または friend(友達)を選択可能。
それぞれの役割定義は以下の通り
teacher: `
You are an English conversation teacher.
English is the only language you speak.
Your main goal is to help the user learn and practice English through roleplay and guided conversation.
Be encouraging and supportive.
friend: `
You are a native English-speaking friend.
English is the only language you speak.
Your main goal is to have a fun, casual, and engaging conversation. So Ignore minor grammatical mistakes and just continue the conversation naturally.
Focus on back-and-forth chatting about various topics like real friends do.
REQ-3.1.2.5 音声選択: Puck, Aoede などのプリセットから選択可能。
REQ-3.1.2.6 創造性(Creativity): Temperature値をスライダーで調整可能。
REQ-3.1.3 音声制御:
REQ-3.1.3.1 エコーキャンセル: echoCancellation: true を有効化。
REQ-3.1.3.2 Barge-in対応: ユーザーの発話を検知した瞬間、AIの音声を即座に停止する。
REQ-3.2 学習・管理機能
REQ-3.2.1 リアルタイム字幕: 会話内容を話者別に吹き出しで囲い、リアルタイムでテキスト化して表示する。ON/OFFの切り替えが可能。
REQ-3.2.2 利用制限機能:
REQ-3.2.2.1 セッション数制限: 1日の最大回数を制限し、超過時はユーザーに通知(現在は最大250回)。
REQ-3.2.2.2 セッション時間制限: 1回の会話時間を制限(1?15分で設定可能)し、経過時に自動停止する。
REQ-3.2.3 統計・履歴機能: 当日のセッション数、合計会話時間、ユーザー発話時間を集計・表示する。過去7日間の履歴を確認可能とする。
第4章:画面構成(UI/UX)
REQ-4-1 画面構成
REQ-4.1.1 「設定画面」と「メイン会話画面」の2画面構成。
REQ-4.1.2 ミニマルなスタイリッシュなデザインを基調とする。
REQ-4.2 設定画面
REQ-4.2.1 インターフェース構成: アコーディオン形式を採用し、キャラクター・レベル設定やAPIキー管理、利用規約同意、利用統計を一箇所で確認・変更できる構成とする。
REQ-4.3 メイン会話画面
REQ-4.3.1 ステータス可視化: Listening/Thinking/Speaking の各状態を波形アニメーションで表現する。
REQ-4.3.2 字幕の表示を行う。可視化したステータス表示の下に、デザイン性を損なわない範囲でできるだけ広い枠を確保する。
第5章:セキュリティ・非機能要件
REQ-5.1 データプライバシー
REQ-5.1.1 利用規約同意: 初回利用時に、Google規約およびデータ送信に関する同意チェックを必須とする。
REQ-5.2 パフォーマンス・消費電力
REQ-5.2.1 省電力設計: 会話停止時や非アクティブ時の不要なレンダリング・オーディオ処理を停止し、モバイル端末のバッテリー消費を抑制する。
第6章:運用・エラー対応
REQ-6.1 エラー表示
REQ-6.1.1 APIのレート制限到達のエラー: 制限到達時、画面上に「API制限中」のオーバーレイを表示し、ユーザーに状況を明示する。
REQ-6.1.2 その他接続エラー: サーバーダウンやタイムアウト発生時、適切なメッセージを表示する。
4つのステップで進めた、着実な開発工程
生成AIに一度に大量のコーディングを依頼すると、モデルが処理できる情報量の限界や、一度に出力できるトークン(文字)数の上限により、正しいコードが生成されない懸念があります。結果として、デバッグ・コストが大きな不完全なコードが出力される可能性が高まります。
そこで、開発要件を固めたうえで、ステップを刻んでコーディングを進めるように、AIに依頼することにしました。
STEP 1:根/幹(Root/Trunk)- 通信機能の実装
まずは、ユーザーとAIの音声通話を確立する土台のステップです。WebSocketによるLive API接続と、音声の双方向ストリーミングを実装します
STEP 2:枝(Trunk)- 機能拡充
次に、設定画面、音声操作、ステータス表示、字幕生成など、ユーザーインターフェースに関する機能を拡充するステップです。
- 話者(AI)の設定:話者の英語のレベル、役割(先生/友達)、声質など選択可能にしました。
- リアルタイム字幕: AIが話した内容を即座に画面に表示。
- 状態の可視化: AIが今「聞いている」のか「考えている」のかをインジケーターで表示し、AIのステータスがわかるようにしました。
STEP 3:葉(Leaf)- PCフル機能の実装
要件定義に準拠し、PC版として運用するために必要な未着手項目をすべて対応するステップです。
- 利用量の見える化: 利用量を明示し、どれだけの時間学習したか、無料利用枠がどれだけ残っているかをわかるようにしました。
- 発話時間の計測: 自分が実際に英語を話した時間を集計。
STEP 4:花(Flower)- モバイル(Android)展開
最後に、Androidスマホで快適に使うための仕上げです。Android環境への移植を行い、インストール可能なAPK形式への書き出しに対応します。
いざ、実装・検証
ここから実装です。私の方で行ったことは、
・開発要件の定義をAIと共有(テキストファイルを開発フォルダに置き、その置き場所をAIに通知)
・開発の上記の4ステップで開発することも共有した上で、
・今回STEP N (N=1,2,3, 4)の実装を推進して下さい、と4回に分けて依頼する。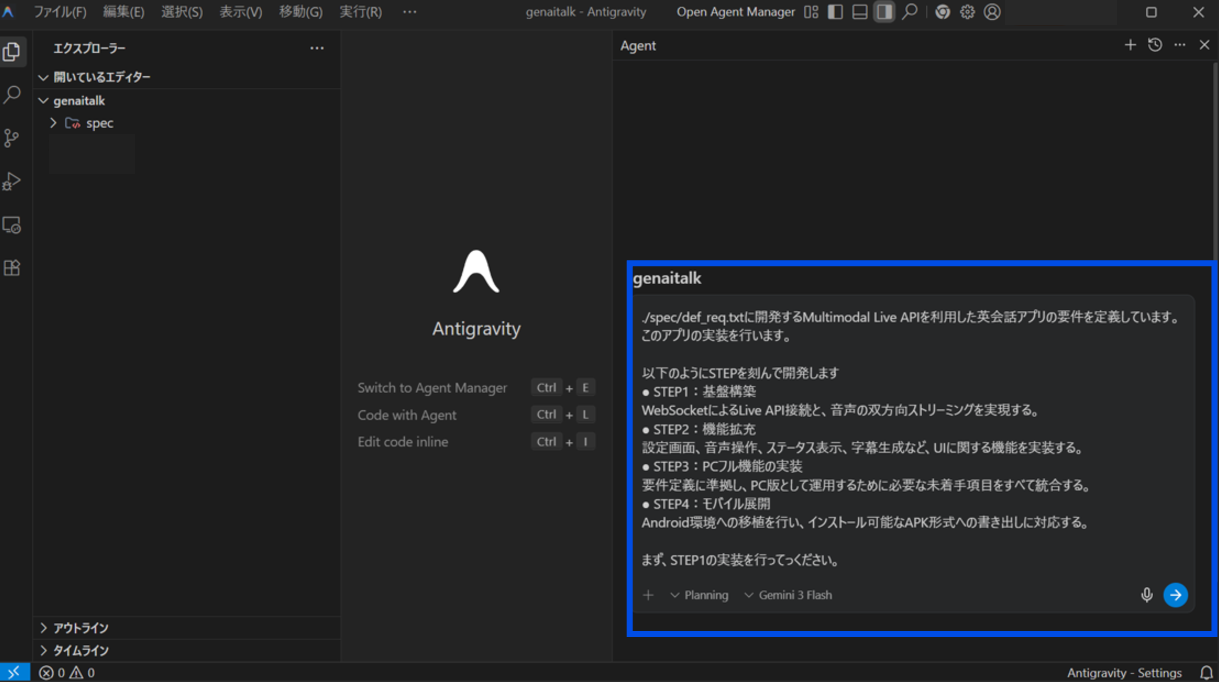
処理を開始する前に、動作モード、使用するモデルの設定をします。
今回は、動作モードは「planning」のまま、モデルは「Gemini 3 flash」 → 「Gemini 3.1 Pro (High)」としました。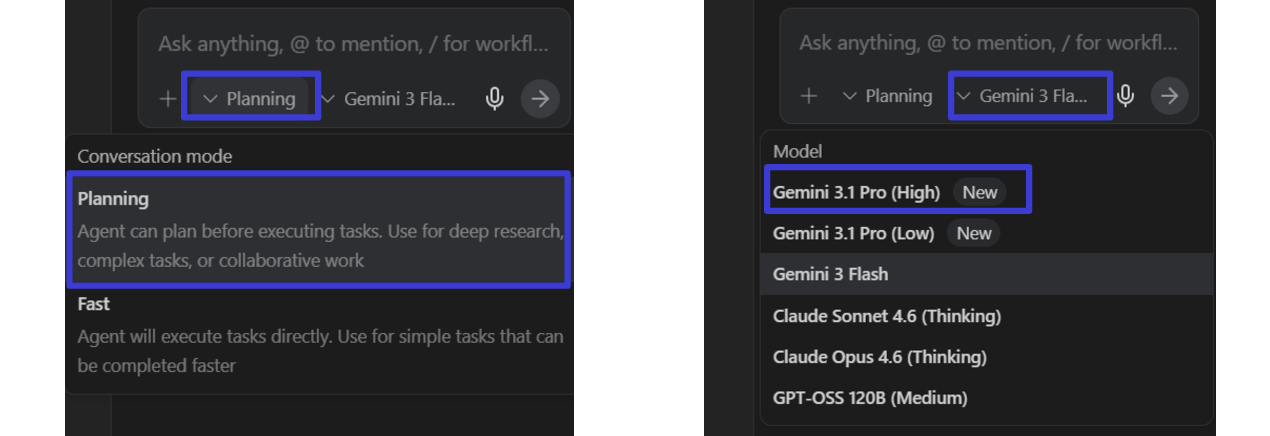
いよいよ処理開始!あとはAntigravityが要件定義のテキストを読み込み、今進めるべきステップを自動で判断して、コーディングをどんどん進めてくれました。
例えば、英語のレベル(初級〜上級)や役割(先生・友達)といった切り替え機能。これらは会話開始時に「内部命令(システムプロンプト)」で制御する仕組みなのですが、私は要件にその希望を書いただけで、具体的なコードの実装はすべてパートナーであるAntigravityにお任せです。
もちろん、途中で不具合や技術的な壁にぶつかることもありましたが、そんな時はGemini Proと対話を重ねることで一つずつクリア。まさにAIと二人三脚で形にしたのが、このアプリです。

今回、GUIのデザインに関しては「ミニマルなスタイリッシュなデザイン」と言った程度で、細かな指示を出さなかったのですが、結果として期待を上回る仕上がりになり、個人的にも非常に満足しています。
明確なビジョンがあるのなら具体的に指示すべきですが、特にこだわりがない場合は、あえてAIに「おまかせ」してみるのも一つの手です。2025年以降に出てきた最新鋭の生成AIについては、自分で中途半端に考え指示を与えるよりも、人が大枠を決めAIに思考を委ねた方が質の高いアウトプットが得られると言われていますが、今回まさにその通りだと実感しました。
最後に、今回のアプリ実装後の動作確認・改善の取り組みで一番苦慮したポイントを「参考:アプリ改良の取り組み」として掲載しているので、興味のある方は覗いてみてください。
▶️参考:アプリ改良の取り組み
(クリックで詳細を表示)
システムプロンプトだけでは実現できなかった「阿吽(あうん)の間」
プロトタイプの実装を経て、各機能が意図通りに動作するか検証を行いました。基本動作は良好でしたが、どうしても一点だけ、従来のプロンプト制御では解決できない課題が浮き彫りになりました。
それは、ユーザーが発話に詰まった時の「間の取り方」です。
本アプリではシステムプロンプトを用い、「ユーザーは英語に不慣れで言葉に詰まることがあるため、即座に応答せず、少し間を置いてからフォローしてほしい」と指示を出しました。しかし結果は、AIがユーザーの発話を延々と待ち続けてしまい、会話が完全に止まってしまうというものでした。
この挙動の真因を探るべく、開発パートナーである生成AI(Gemini 3.1 Pro)と構造分析を実施したところ、Live APIが抱える根本的な特性が見えてきました。
- Live APIの根本的特性: Gemini 2.5 Flash Native AudioなどのLive APIは、本質的に「受け取った入力に対して回答を生成する」というリクエスト・リプライ型のモデルであり、AI側が自律的に発話を開始する機能(内部時計によるトリガー)を持っていません。
- プロンプトの限界: AIにとっての「沈黙」は「入力がない状態」を意味します。入力がない限りAIの処理サイクルが回らないため、いくらプロンプトで「沈黙時に話して」と指示しても、その命令自体が実行されないという論理的な矛盾が生じている。
この分析を経て、「沈黙後の会話の再開をAIの自発性に頼るのではなく、システム側からAIに発話のきっかけ(トリガー)を与える」という解決策を策定しました。
【解決策:3つのレイヤーによる沈黙回避メカニズム】
「雑音には過剰に反応せず、必要なタイミングで自然にAIが会話をリードする」という人間らしい対話を実現するため、システムを「物理・論理・振る舞い」の3つの階層に分けて構築しました。
✅ 音の検知レイヤー(物理判定:サーバー主導VAD)
- 役割: 人間の声と雑音を区別し、人間の音声の「発話の区切り」を捉える。
- 詳細: 単純な音量判定では環境音に誤反応してしまうため、Googleサーバー側に搭載されたVAD(音声区間検出)を活用しています。これにより「人間の声」だけを抽出し、ノイズを無視した上で、ユーザーが話し終えたタイミング(無音状態)を検知してシステムに通知します。
✅ 時間管理のレイヤー(論理制御:フォローアップタイマー)
- 役割: ユーザーの沈黙が長く続いた際に、AIから働きかけるための「きっかけ」を作る。
- 詳細: AI側からは自発的に発話を開始できない仕様を補うため、アプリ側に独自の沈黙計測タイマーを実装しています。AIが聞き取り状態になった瞬間や、ユーザーの発話の区切りを検知した瞬間にカウントを開始します。設定した秒数が経過すると、アプリからAIへ発話のトリガとなるシグナルを送信します。なお、このタイマーは誰かが話し始めるか、AIが処理を開始すると即座にリセットされます。
✅ 意味の判断レイヤー(振る舞い制御:システムプロンプト)
- 役割:
会話の文脈を理解し、「待つべきか」「話し出すべきか」を判断する。 - 詳細:
レイヤー1(VAD)から発話の区切りが通知されると、AIはシステムプロンプトの指示に従い、それまで話された内容からユーザーの意図を分析し、以下の通り柔軟に振る舞いを変えます。
- 発話が完了したと判断した場合:
通常通り回答を生成し、話し始めます。 - 発話の途中だと判断した場合:
あえて話し出さず、ユーザーの次の言葉をそのまま待ちます。
待ち続けていると時間管理レイヤーのタイマーが発火し、アプリからシグナルを受け取ります。AIは「ユーザーが言葉に詰まっている」と解釈し、そのシグナルに応じて会話を促すようなフォローの発話を自発的に行います。
この対策をアプリに組み込むことにより、意図通りの間を実現できるようになりました。
おわりに:AIとの「共創」が広げるアプリ共有の可能性
Geminiとの英会話で感じた「あともう少しこうなれば」という小さなストレス。それを解消する手段として、今回は「自分の理想に合わせたアプリを自作する」というアプローチを試しました。
既存のサービスに自分を合わせるのではなく、システムプロンプトや細かい動作ルールを自分で定義することで、標準機能では難しかった「自分にちょうどいい間の取り方」や「レベルに応じた厳しさ」を実装することができました。驚くべきは、これら一連の開発工程において、私自身はコードを一行も書いていないという点です。
もちろん、AIに丸投げしたわけではありません。どんなものを作りたいかという機能面での要求が明確に定まっていたのでその点は「要件」を細かく整理しAIに指示しました。ただし、デザインを含め指示をしていない部分も多々あります。しかし、エージェント型AIである「Antigravity」のようなツールを活用すれば、プログラミングスキルの壁を越え、且つ仕様がブラックボックスの部分は自らソリューションを出し、形にしてくれます。自分の理想を形にできる段階にきているのは確かです。
「既存のツールでは物足りない」と感じたとき、それを自分でカスタマイズしたり、一から構築したりする。そんなAIとの共創による新しいツールづくりが、これからのスタンダードになっていくのかもしれません。
また、今回の開発で改めて課題として痛感したのが「検証」にかかるコストです。せっかく作ったアプリを、誰もが安心して使える品質まで高め、不具合を取り除く(デバッグする)には、依然として高いハードルが存在します。
もし、多様な端末の画面サイズやOS、不安定な通信環境などへの対応といった、複雑な検証作業をAIが自動でこなしてくれる環境さえ整えば、開発のあり方は劇的に変わるはずです。そうなれば、個人が自分のために生み出した「理想のツール」を、誰もが自由に分かち合い、手軽に役立て合える――。そんなワクワクするような時代が、すぐそこまで来ていることを確信しています。
